内容目录
java
5、第五章 ThreadLocal 与 HashMap
5.1 ThreadLocal

5.2 我们经常使用的 HashMap,说说你对它的理解和认识?
1、整体类继承结构
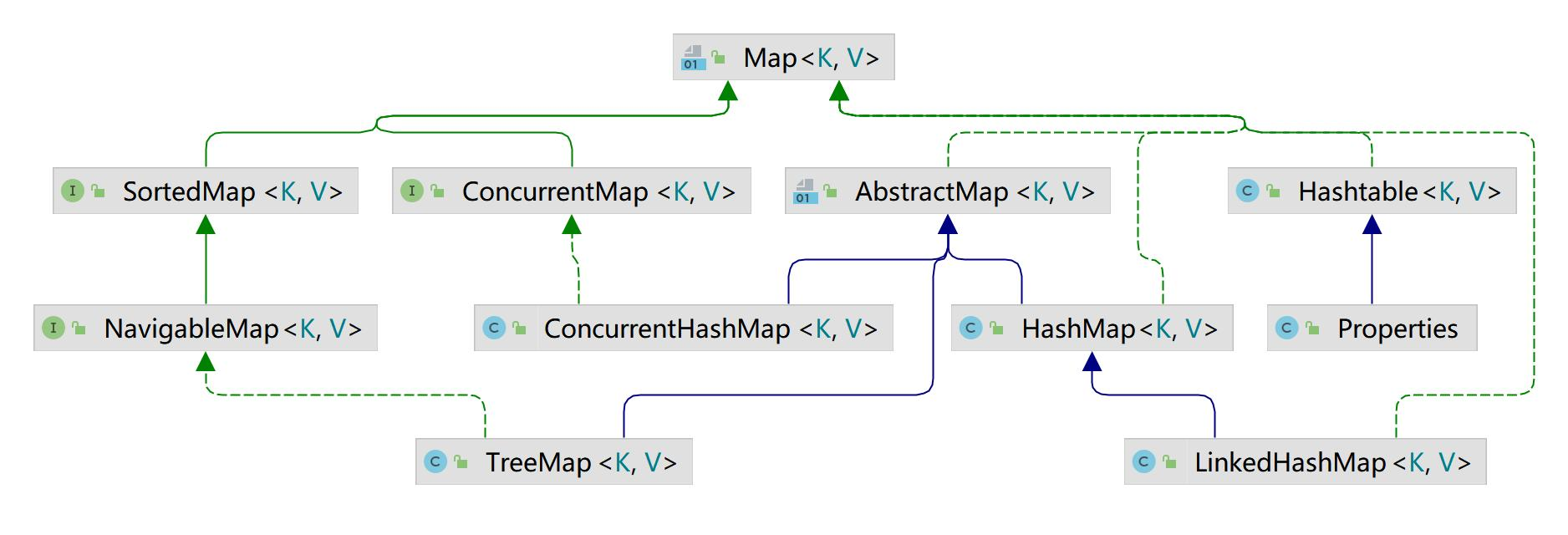
2、主要特点
(1) 数据以键值(key-value)对方式存储的一个集合容器;
(2) Key 不重复;
(3) 可以使用 null 的键和 null 的值;
(4) 不保证 key-value 映射的顺序;
(5) 非线程安全实现的;
3、数据结构
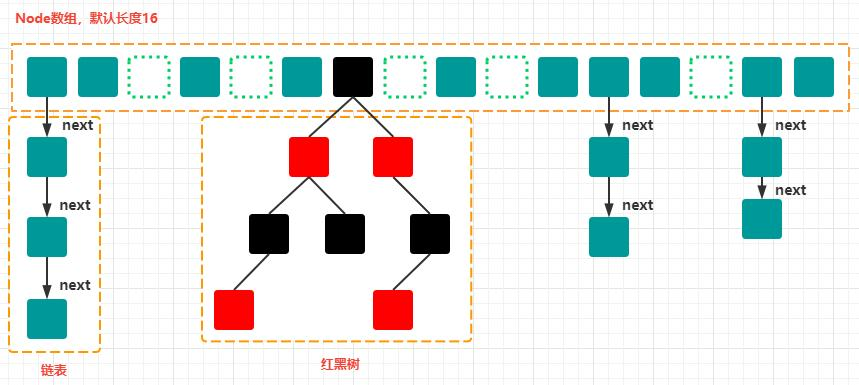
在 JDK1.7 中,由 数组 + 链表 构成;
在 JDK1.8 中,由 数组 + 链表 + 红黑树 构成;
4、HashMap 性能参数
(1)初始容量 capacity:创建数组的长度默认是 16,如果太少,很容易触发扩容,如果太多,遍历数组会比较慢;
(2)负载因子 loadFactor:一个衡量的尺度,数组长度达到多少的时候触发数组自动扩容,默认为 0.75;
(3)阈值 threshold:阈值=容量_负载因子,默认 16_0.75=12,当元素数量超过阈值时触发扩
容;
5.3 多线程条件下 HashMap 有什么问题吗?
2、多线程 put 可能导致元素丢失;
3、put 和 get 并发时,可能导致 get 为 null;
5.4 HashMap 链表节点过深时为什么选择使用红黑树?
2、强平衡二叉查找树 (二叉树)
3、弱平衡二叉查找树 (二叉树)
二叉查找树(Binary Search Trees) BST
特点:
1、每个节点最多只能有两个子节点;
2、左子树的键值小于根的键值(hash 值),右子树的键值大于等于根的键值;
3、对二叉查找树的节点进行查找时,深度为 1 的节点查找次数为 1,深度为 2 节点查找次数为 2,深度为 3 的节点查找次数为 3,深度为 n 的节点查找次数为 n,因此查找时间复杂度依赖于节点深度,如果节点很深,则查找效率降低;
4、极端情况下,如果键值是顺序增大的,则二叉查找树“退化”为像链表的结构;
平衡二叉查找树(AVL Tree)
为了提高二叉查找树的的查找效率,引入了一种新的数据结构:平衡二叉查找树(也叫 AVL 树:1962 年 G. M. Adelson-Velsky 和 E. M. Landis 两个人提出来的);
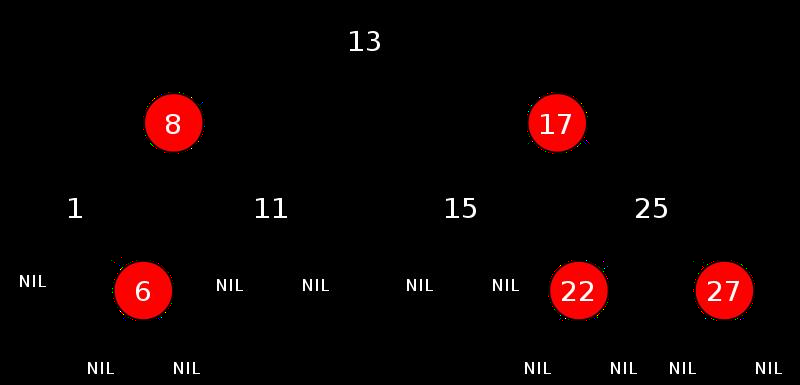
平衡二叉查找树(AVL 树)在满足二叉查找树的条件下,还需满足任何节点的两个子树的高度最大差为 1,所以它呈现出是一种左右平衡的状态;(height <=1) 强平衡, 自平衡
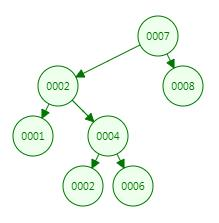
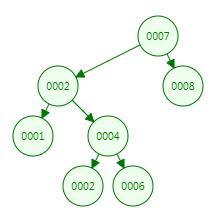
上图中左边的是 AVL 树,它的任何节点的两个子树的高度差<=1;
右边的不是 AVL 树,其根节点的左子树高度为 3,而右子树高度为 1,两个子树的高度差为 2;
当我们向平衡二叉树(AVL Tree)插入新的节点(或者删除新的节点),有可能打破它原有的平衡,那么它会通过旋转使其恢复平衡;
红黑树(red black tree)
(1)每个节点要么是红的要么是黑的;
(2)根节点和叶节点(叶节点即指树尾端 NIL 节点)都是黑的;
(3)如果一个结点是红的,那么它的两个子节点都是黑的(不可能连续两个红色节点,但是可以连续两个黑色节点);
(4)任意节点到叶节点的链路中都包含相同数目的黑节点;
红黑树与 AVL 树的比较
弱AVL 树由于追求强平衡所付出的代价较大,因此实际应用不多,更多的是使用追求局部平衡的红黑树;
在相同节点个数的情况下,AVL 树的高度<=红黑树,如果应用只是对查找要求较高,那么 AVL 树要优于红黑树;
HashMap 之所以选择红黑树是对比了二叉查找树、平衡二叉查找树,二叉查找树在特殊情况下会变成一条线性结构(这就跟原来使用链表结构一样了,造成很深的问题),遍历查找会非常慢;
而平衡二叉查找树维持这种“强平衡”需要需要付出代价;
5.5 什么是 hash 碰撞,发生 hash 碰撞怎么办?
哈希碰撞哈希冲突现在我们有一组数:{18,23,5,32,50,14,34,39,11}
假设我们的 hash 函数是按照数组长度取余的方式计算:
18%16=2
23%16=7
5%16=5
32%16=0
50%16=2
14%16=14
34%16=2
39%16=7
11%16=11

一般哈希冲突只能尽量地减少,无法完全避免,因为关键字在理论上可以有无限多个,而用来存储这些关键字的数组容量是有限的,所以就必然会导致了哈希冲突,只能通过选择合适的哈希函数来降低哈希冲突发生的概率;
Hash 冲突的解决办法:
1、开放定址法;
开放定址法是指当发生哈希冲突的时候,按照某种方法继续探测哈希表中的其他存储位置,一直找到空位置为止;
比如在插入 50 这个元素时,发现要插入的位置已经存在元素了,我们用开放定址法来解决这个哈希冲突;
过程分析:
第一次计算 50 要插入的是 2 号位置,而 2 号位置已经存在元素 18 了,那么就将 2 加 1 得到 3,
然后再查看 3 号位置是否有元素,发现 3 号位置是空的,那么就可以把 50 这个元素放在 3 号位置了;
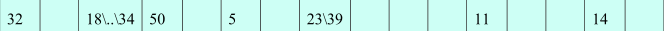
2、再哈希法;
当发生哈希冲突的时候就再次哈希,直至不发生冲突为止;
3、链地址法(拉链法)--> HashMap 采用是该办法
链地址法是指碰到哈希冲突的时候,将冲突的元素以链表的形式进行存储,也就是只要哈希地址相同的元素,都插入到同一个链表中,元素的插入方式可以是头插法,也可以是尾插法;
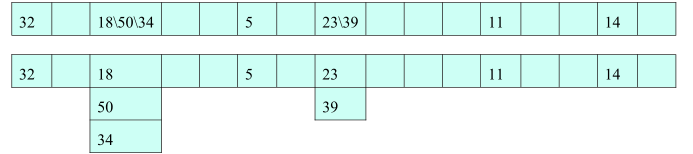
链地址法是比较常用的一种解决哈希冲突的方式,HashMap 采用的是这种链地址法(拉链法),当发生冲突时,将新结点添加在链表后面;
虽然这是一种不错的处理方式,但是也存在一些明显的弊端,在极端情况下,他的查询时间复杂度还是会达到 O(n)级别,此时哈希表已经退化成了一个普通的链表,在这种结构下去查找一个元素,时间复杂度是 O(n),因此,在链表达到一定长度的时候,把链表转化成一棵树可以提高查找效率,HashMap 的源码中就是这么实现的,当数组的长度大于 64,且数组某个位置上的链表的长度大于 8 时,就会把数组某个位置上的链表转换成一棵红黑树(O(logN));
5.6 ConcurrentHashMap
JDK 1.7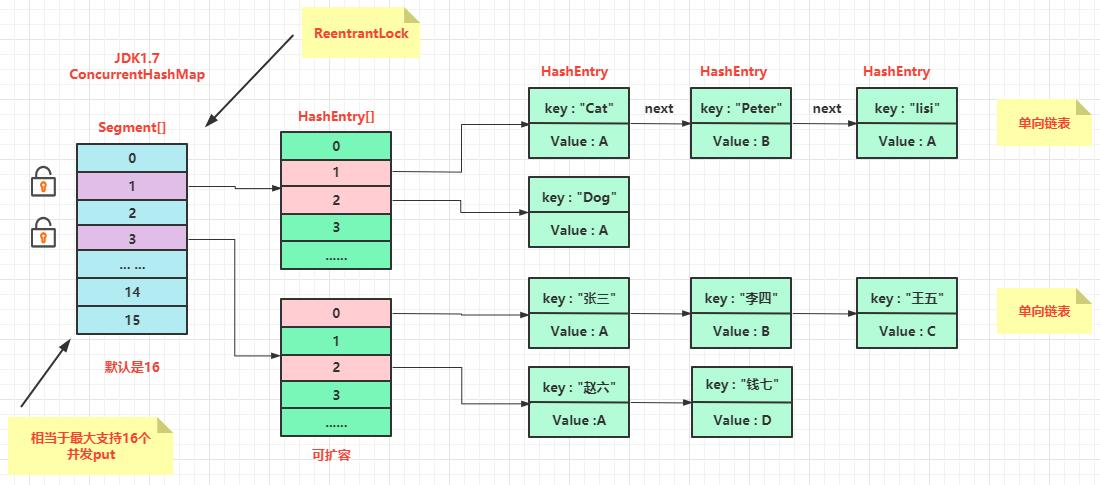
JDK 1.8
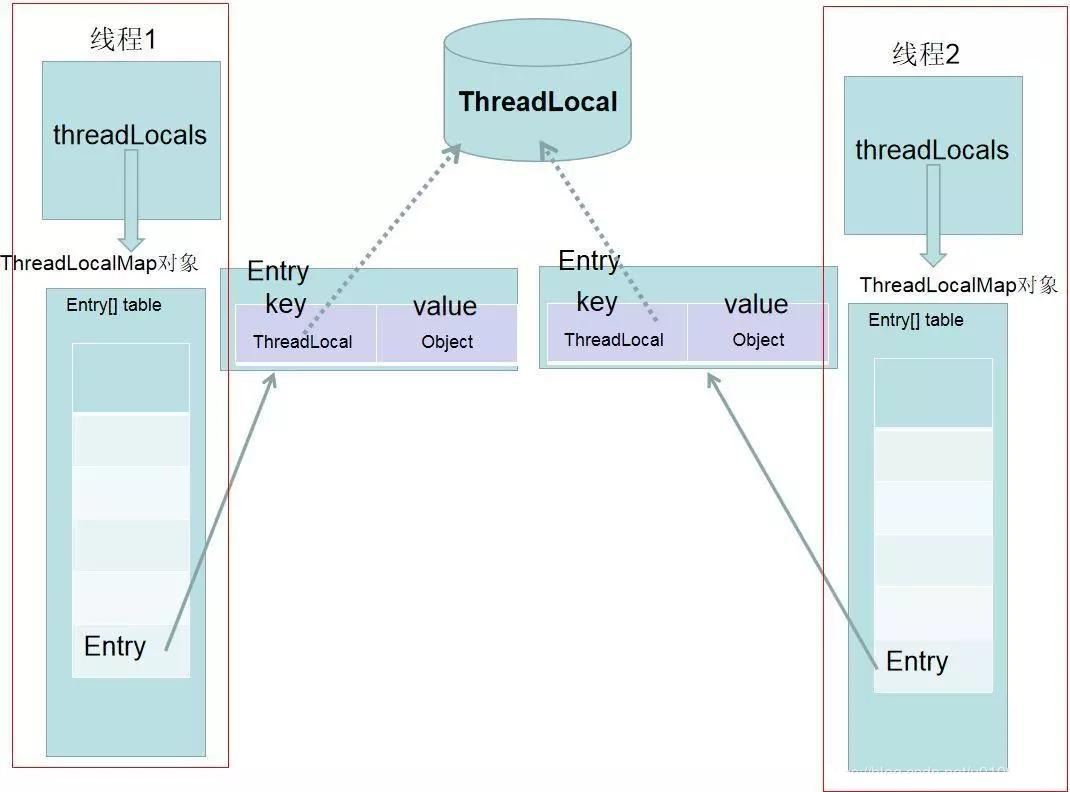
5.7 ThreadLocal 的实现原理? 为什么会内存泄漏?
Threadlocal 的实现原理就是通过 set 把 value set 到线程的 threadlocals 属性中,threadlocals 是一个 Map,其中的 key 是 ThreadLocal 的 this 引用,value 是我们所 set 的值,如果当前线程不销毁的话,threadlocals 会一直存在,一直存在的话可能会造成内存溢出,所以使用完之后尽量 remove;
内存泄漏 memory leak :是指程序在申请内存后,未释放或者无法释放已申请的内存空间,一次内存泄漏似乎不会有大的影响,但内存泄漏堆积后的后果就是内存溢出;
内存溢出 out of memory :没有多余内存可以分配给新的对象了;